In our last post, we showed that CipherStor’s performance is extremely fast. So fast, that other system bottlenecks such as SSD storage IO or network IO begin to surface. In light of that, we wanted to have a blog post on how to encrypt large files efficiently.
We recently had a discussion where a customer used the CipherStor API to write a worker process (let’s call it “CipherStorWorker”) which would consume the result of the business logic process (let’s call it “BusinessLogicWorker”). Conceptually, this reminds me of pipelined vs non-pipelined microprocessor architectures, so I’ll borrow those terms. Diagrammatically this is shown below.
Non-pipelined approach
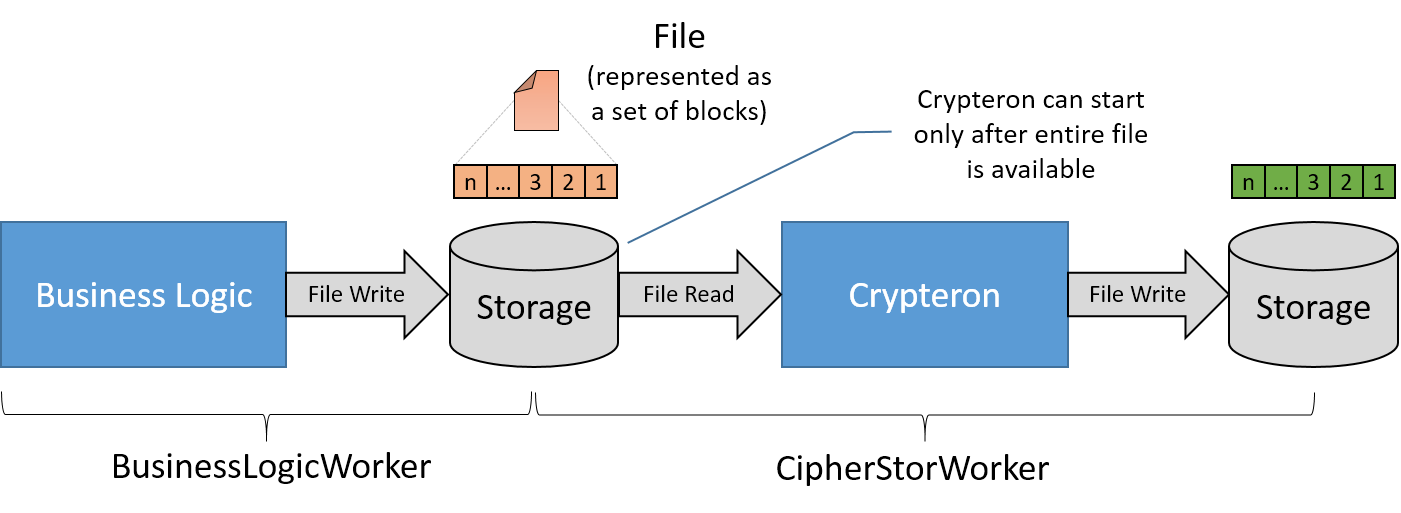
Of course, when illustrated this way, it’s easy to spot the issue. We’re hitting storage 3 times – two writes and one read. Considering that the storage bandwidth is the typical system bottleneck, this approach takes that severe bottleneck and makes it three time worse (!). The BusinessLogicWorker and CipherStorWorker will both be idle, waiting for the storage to catch up. This leads to significantly longer end-to-end job execution times. In fact, Crypteron cannot even start until the entire file is processed AND written by Business Logic to the storage medium.
Pipelined approach
A far better approach is to incorporate the CipherStor APIs into the BusinessLogicWorker directly before any block ever hits the storage systems. This is conceptually shown below.
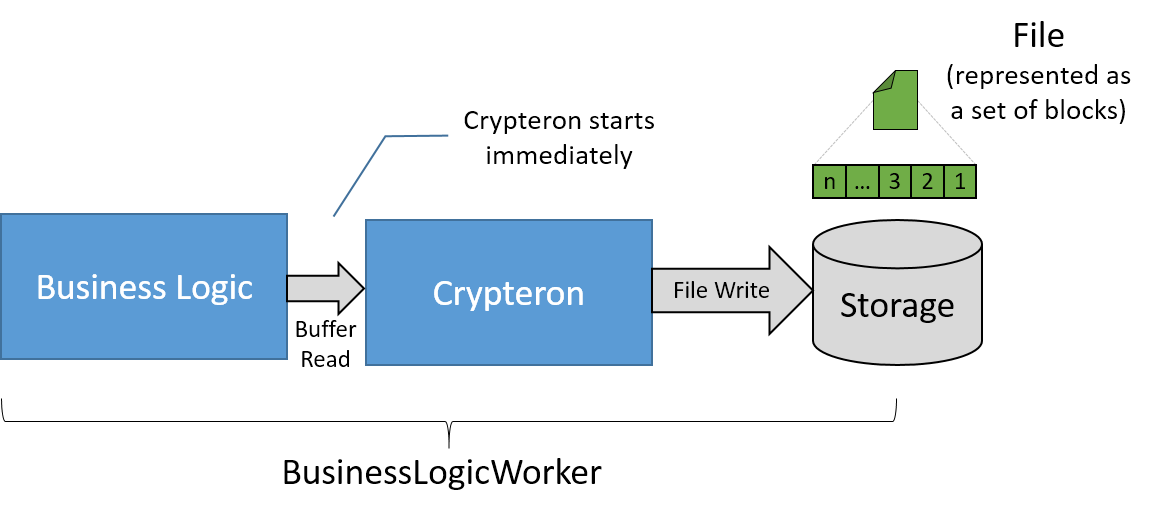
By using the steaming API to pass raw data from the business logic core to Crypteron’s CipherStor, one is effectively bypassing storage IO bottlenecks. As soon as a block is processed by the Business Logic core, it is immediately handed off to Crypteron. The Business Logic core moves to the next block and this clockwork continues until the last block flows through the system. So instead of waiting for the entire file to be first written out, Crypteron begins its work almost immediately.
Not only is this approach faster, it’s significantly secure since a plaintext version of the file never hits the storage systems.
Storage Bottleneck gone?
It’s worth saying that ultimately the data is written to storage, possibly over the network (e.g. SANs, Amazon S3, Azure BLOB etc). So there is no escaping those bottlenecks but by pipelining the processing of the entire file, we’re at least making sure we’re not amplifying that bottleneck problem. If you’re consistently seeing your storage or network bandwidth slow things down, the obvious thing to look into is upgrading to faster storage or bandwidth. If that’s not a possibility, another approach would be to add additional BusinessLogicWorkers in parallel across multiple VMs (i.e. ‘scale out’), so your outgoing network bandwidth scales up too. A full discussion of possible architectures is outside the scope of this blog post but if you’re interested, you might want to read more on Netflix’ cloud architecture.










